

Uma dúvida, que eu tive muito no início da minha carreira como DBA, e que muitas pessoas podem ter é referente ao MAXDOP. Eu particularmente adoro saber o que faz cada processo, porém amo mais ainda entender a fundo como a configuração e cada processo funcionam.
Com o intuito de ajudar quem já teve essa dúvida, nesse artigo falaremos sobre Paralelismo. Para iniciarmos o assunto precisamos entender o que é o processamento paralelo.
O processamento paralelo tem como objetivo quebrar tarefas grandes em pequenas tarefas, o SQLServer usa essa mesma lógica, pega processos com cargas de trabalho excessiva e processa de forma paralela.
O Query Optimizer leva em conta três configurações ao gerar um plano de execução que se beneficie de processamento paralelo. São elas:
- Limite de custo para o paralelismo
- Grau máximo de paralelismo (MAXDOP)
- Máscara de Afinidade (Affinity Mask)
Agora que já entendemos um pouco de processamento paralelo, precisamos entender o que é MAXDOP!
Grau máximo de paralelismo, ou (MAXDOP), é um parâmetro que pode ser configurado a nível de servidor, de banco ou de consulta, para determinar o número máximo de processadores lógicos, que podem ser utilizados para consultas candidatas a um plano de execução paralelo. Por padrão o valor para o parâmetro MAXDOP é 0.
Cost Threshold for Parallelism é um parâmetro que o Query Optimizer utiliza para criar planos de execução para consultas candidatas a paralelismo. O SQLServer executa os planos de execução paralelos, criados pelo Query Optimizer, somente quando o custo estimando para criar um plano serial for maior do que o valor do parâmetro Cost Threshold for Parallelism.
O Cost Threshold for Parallelism pode ser definido com valores entre 0 e 32767, por default esse valor vem setado como 5. Ele pode ser configurado e visualizado a nível de instância e através da sp_configure.
Antes de configurarmos o MAXDOP, por boas práticas para acharmos o valor ideal para o MAXDOP temos que calcular, utilizando a metade da quantidade de processadores por NUMA NODE, assim, encontraremos o valor ideal para o MAXDOP!
Interessante as informações acima, e como poderíamos configurar o MAXDOP, e o Cost Threshold for Parellelism?
Exemplo 1:
A nível de instância e temos as duas formas abaixo:

Exemplo 2:
A nível de consulta:

Exemplo 3:
A nível de banco de dados, podemos configurar das duas formas abaixo:

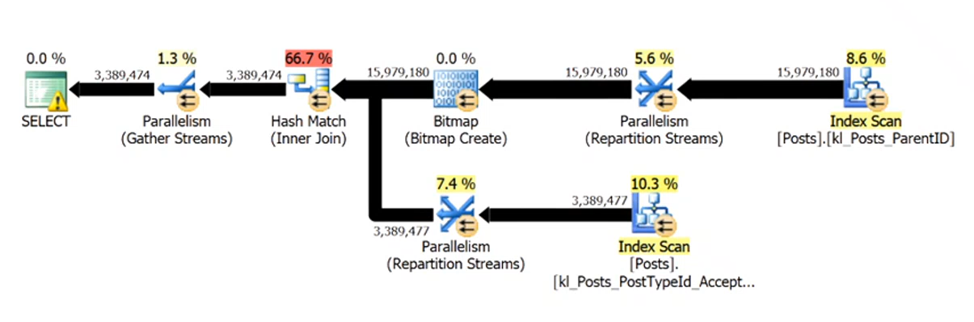
Quando analisamos um plano de execução é fácil identificar consultas que se beneficiam do uso de paralelismo, uma das formas de identificar e através dos Exchanges Operators(Operadores de troca). Nas imagens a seguir vamos falar um pouco dessses operadores e como eles funcionam:


Outra forma rápida para identificar consultas que fazem paralelismo, é através do Wait CXPACKET. O que esse Wait Type?
CXPACKET – O tempo de espera elevado nesse Wait indica que estão ocorrendo ou ocorreram operações utilizando plano de execução paralelo. Se a espera for excessiva, e não puder ser reduzida através do ajuste da consulta, com a criação de índices por exemplo, considere ajustar o Cost Threshold for Parallelism e o MAXDOP.
Demo 1:
Abaixo vamos rodar uma consultas utilizando paralelismo com as configurações padrões do SQLServer. Não sei se lembram anteriormente, falamos que por padrão o Cost Threshold for Parallelism vem com o valor = 5. Em alguns casos, um plano paralelo pode ser escolhido mesmo que o plano de custo da consulta seja menor que o Cost Threshold atual para o valor de paralelismo. Isso pode acontecer porque a decisão de usar um plano paralelo ou serial é baseada em uma estimativa de custo fornecida anteriormente no processo de otimização.
Na execução da demo 1, nosso Degree of Parallelism está como 8, isso significa que como deixamos o valor que vem por default para o SQL Server, e ele está utilizando todos os meus processadores para executar a consulta.

Nessa primeira demo, além de nortamos o no CPUTime e Elapsed Time, elevados ocupando todos os Threads, notamos no WaitStats o Wait CXPACKET com maior tempo, rodando uma consulta que pega os Waits, também é possível ver esse Wait com tempo elevado quando existem consultas candidatas a um plano de execução paralelo.
SQL Server Execution Times:
CPU time = 12951 ms, elapsed time = 37489 ms.
Demo 2:
Iremos configurar o MAXDOP, e o Cost Threshold, lembrando que para o meu caso tenho uma NUMA NODE com 8 Processadores, por isso meu maxdop = 4. Podemos notar a diferença em relação a demo 1, que eu deixei os valores default.
--Definir MAXDOP e Cost Threshold EXEC sys.sp_configure @configname = 'show advanced options', @configvalue = 1; RECONFIGURE; EXEC sys.sp_configure @configname = 'cost threshold for parallelism', @configvalue = 10; RECONFIGURE; EXEC sys.sp_configure @configname = 'max degree of parallelism', @configvalue = 4; RECONFIGURE;

Utilizando agora a configuração recomendada por NUMA NODE, temos um CPUTime menor do que na Demo 1.
SQL Server Execution Times:
CPU time = 10657 ms, elapsed time = 37545 ms.
Demo 3:
Iremos configurar o MAXDOP, e o Cost Threshold, utilizando um exemplo que já vi sendo utilizado em alguns lugares. alterando o MAXDOP para 2 e testando. Podemos notar que utilizando 2 processadores o meu Estimated Subtree Cost aumentou.

Nessa demo o nosso CPUTime reduziu, porém temos um Elapsed Time maior, do que em demos anteriores.
SQL Server Execution Times:
CPU time = 9000 ms, elapsed time = 38521 ms.
Demo 4 :
O que acontece se colocarmos o MAXDOP, com o valor 1, será que utilizará somente 1 processador e irá melhorar em questões de performance?

Como assim, sumiu o paralelismo?
Na verdade ele foi inibido, porém esse cenário não pode ocorrer, temos que ter esses parâmetros configurados para que as consultas candidatas a um plano de execução paralelo, possam se beneficiar do paralelismo, trazendo a melhor performance. Quando colocamos nosso MAXDOP com o valor 1, o SQLServer suprime o Cost Threshold. Porém isso tem consequencias como podemos notar nos tempos abaixo CPUTime que é quantidade de ciclos de CPU gasto pelos Threads para executar as etapas da instrução, em relação as outras demos, nosso Elapsed Time, que é o tempo total para executar a instrução aumentou, e nosso Estimated Subtree Cost também.
SQL Server Execution Times:
CPU time = 6672 ms, elapsed time = 42960 ms.
Conclusões:
Lógico, nos exemplos acima estou rodando somente uma consulta, então ela não vai se beneficar o máximo de paralelismo, para que isso ocorra eu teria que estar rodando mais consultas em paralelo. É recomendado utilizar a metade de processadores por NUMA NODE como um bom valor para o MAXDOP. Porém o mais ideal seria testar para chegarmos em um Degree of Parallelim que irá favorecer todas as consultas, ou a maioria das consultas que utilizam paralelismo, para isso é preciso alguns testes, e horas de pesquisa, só então conseguiremos chegar no melhor para cada ambiente de banco de dados.
Espero que esse artigo possa ajudar, e salientar sobre a importancia de se configurar o Cost Threshold e o MAXDOP corretamente. Seguem abaixo algumas referências!
Referências:
Para conhecer mais sobre nossos projetos e sobre as novidades do Universo dos Dados, nos sigas em nossas redes sociais. E aqui no blog DataEX postamos artigos semanalmente, fique atento.
Invista agora em um projeto e transforme os dados do seu negócio em estratégia.
Transforme sua empresa através de uma cultura consistente e 100% baseada em Dados. Com o apoio da DataEX você consegue acelerar sua tomada de decisão e constrói uma nova maneira de organizar e trabalhar com base da ciência de Dados.
Preencha o formulário abaixo e converse com nosso time de especialistas.
